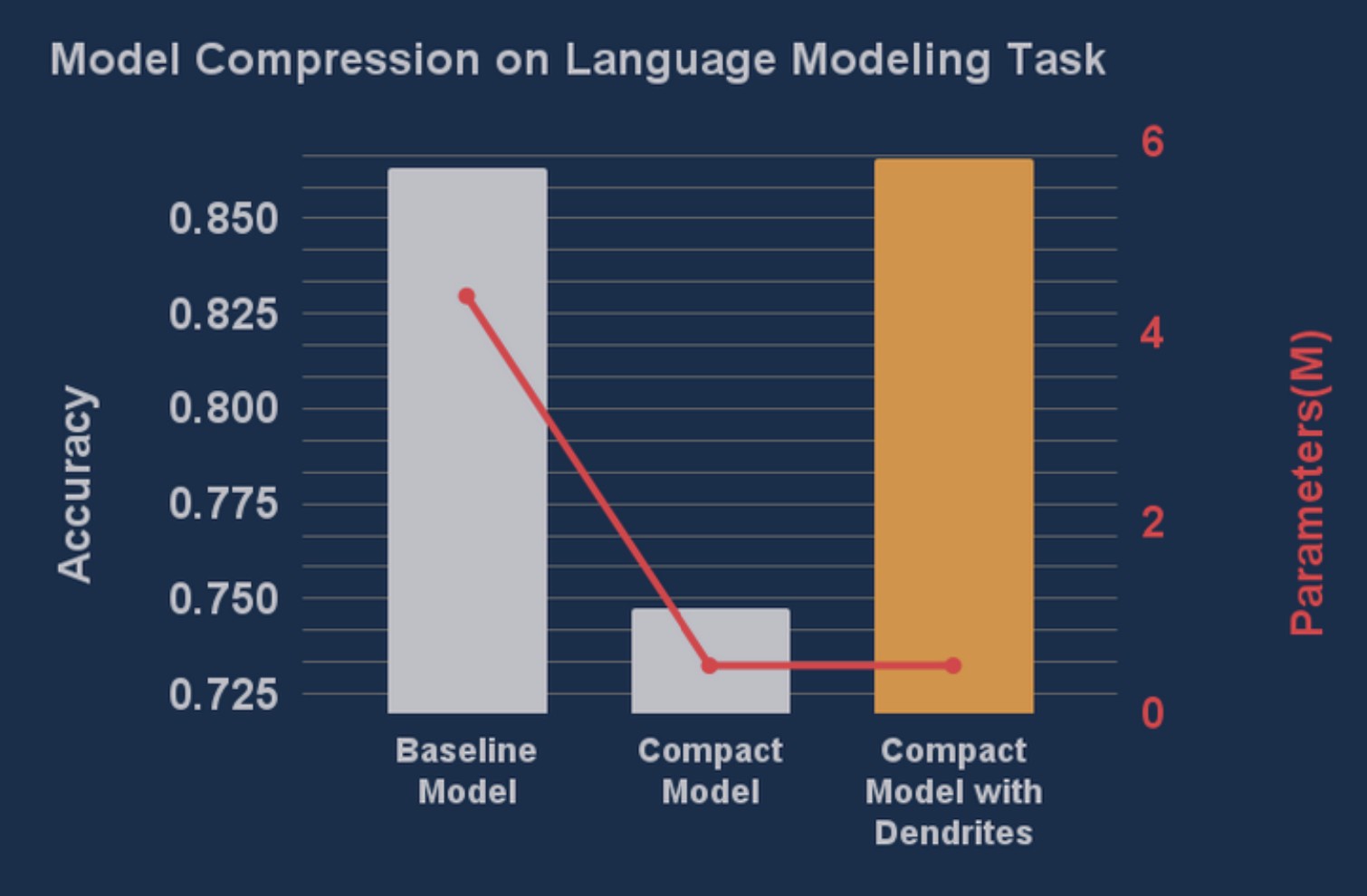
The winner of our hackathon built a BERT based language model that was 90% smaller while delivering slightly higher accuracy on his experimental dataset. After the hackathon was complete we asked Skim AI to actually deploy this model onto various Google Cloud instances to see the real world impact of this new model compared to the old one. The results were staggering.
Experimental Process
In this experiment the original BERT-Tiny model and the new BERT-DSN + PB model were deployed to identical instances on Google-Cloud. In each instance a simple parameter sweep was conducted across the batch size to determine the optimal number of batches to process concurrently in order to maximize the available compute for that instance. Experiments were run on instances with T4, L4, and A100 GPUs as well as instances containing only 4 and 16 vCPUs.
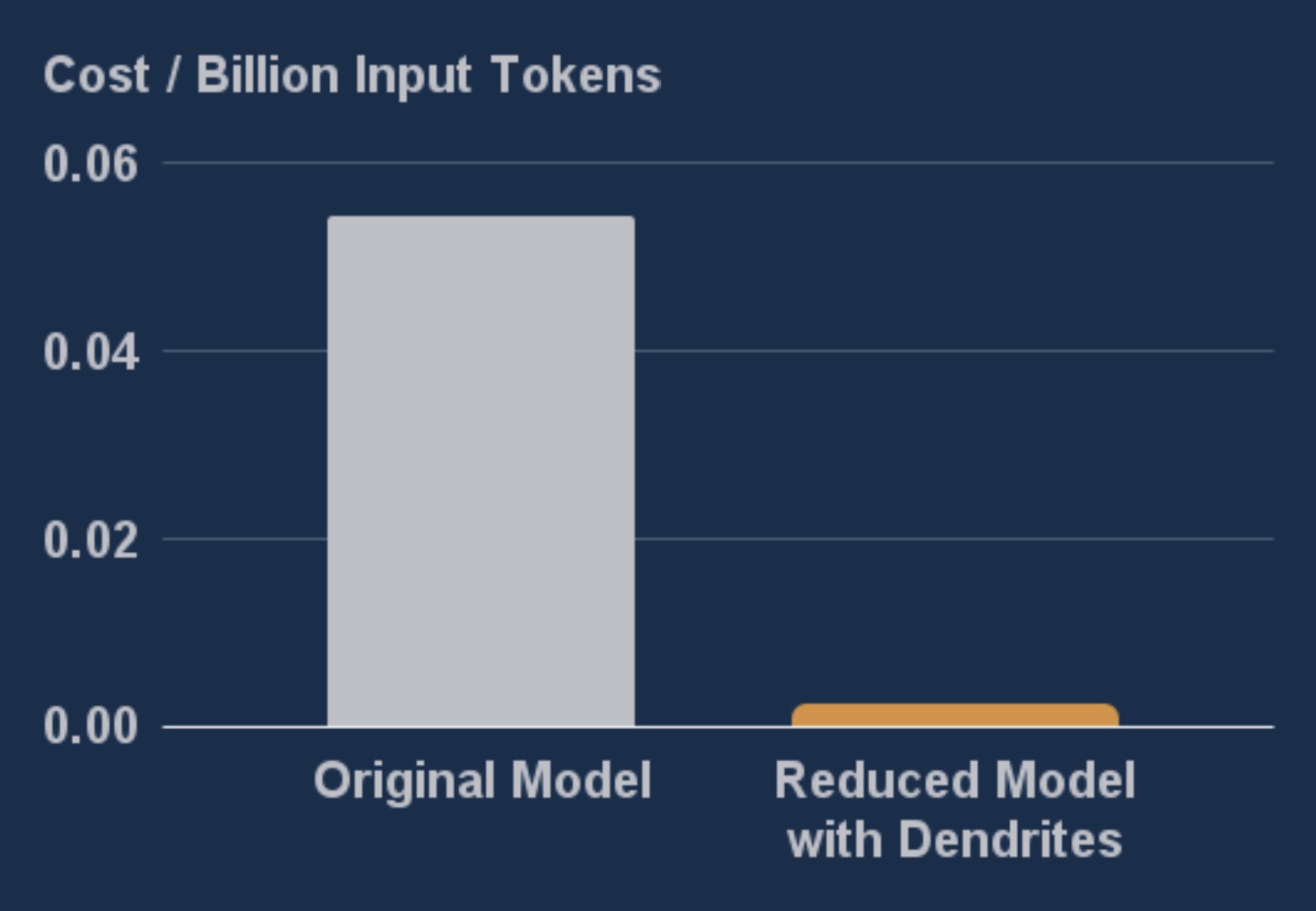
38x improvement in cost efficiency with DSN-BERT + Perforated Backpropagation™
Optimizing Cost
To calculate the cost efficiency a number was determined for each model deployed to each instance for the total number of tokens per hour that could be processed on that instance. Dividing the total cost of the instance by this number granted the cost per token. For both models the T4 instance produced the best cost per token. The instance price is only $0.31 per hour with the original model processing 5.69 billion tokens per hour compared to the optimized model's 215 billion, a 38x improvement. As an extra note, the electrical savings would be proportional to the costs, granting a 38x reduction in carbon footprint as well, supporting the continuation of the current AI trajectory without hurting the planet.
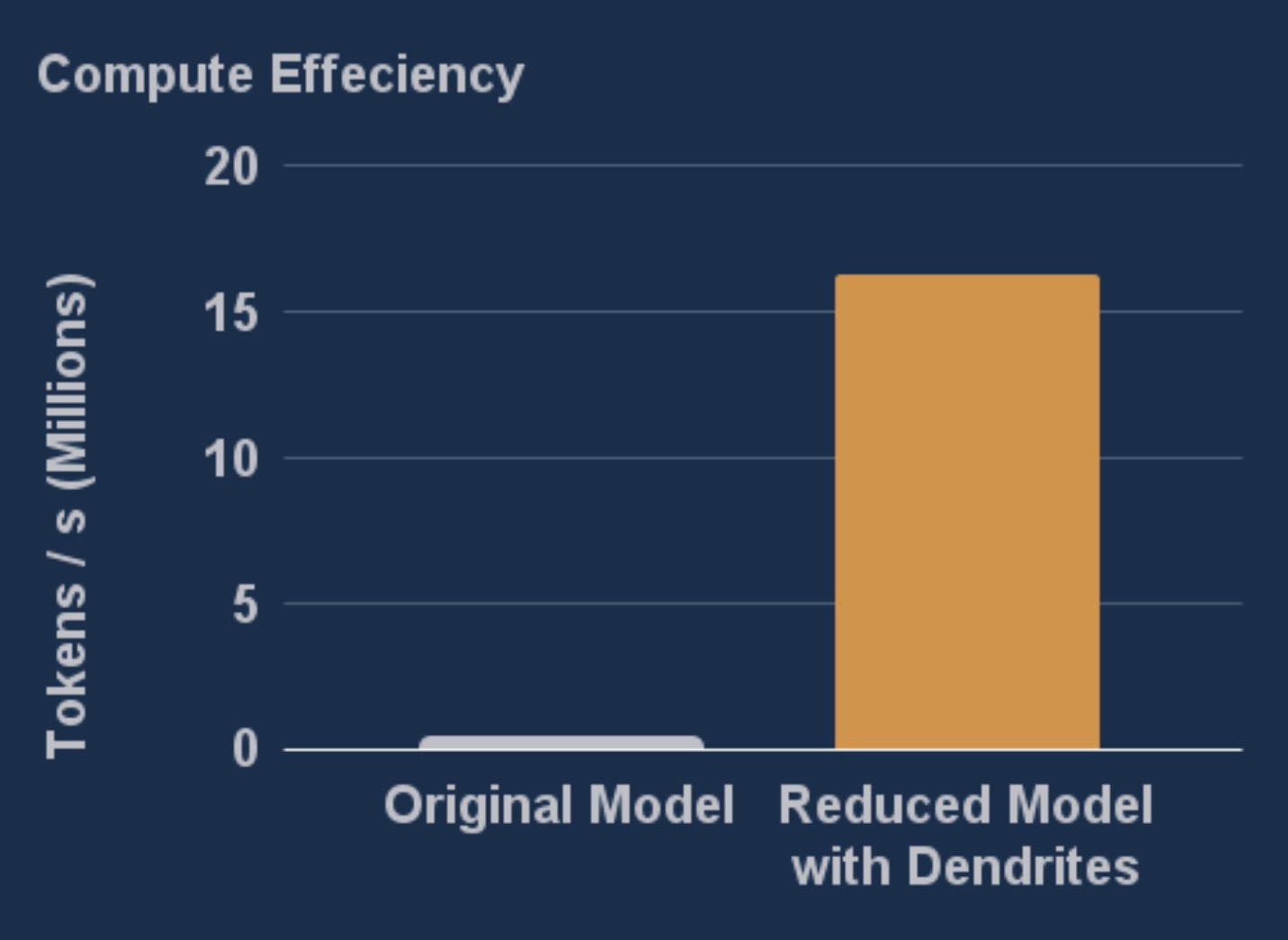
152x improvement in edge device performance enabling on-device deployment
Optimizing for the Edge
In addition to optimizing for cost, many use compression techniques in order to deploy models to edge devices with restricted hardware. To simulate the impact of edge deployment, we're also reporting the numbers achieved on that minimal instance with only 4 vCPUs. Maximizing for tokens processed per second, the original model could handle only 107 thousand, with the optimized model crunching 16 million. This 152x improvement showed the new model is so much faster than the original, its actually still 11 times faster than the original running on the T4 GPU instance, showing evidence that with Perforated AI models that used to require significant cloud infrastructure can now be run right on device.
Key Results
- 38x cost improvement from 5.69 billion to 215 billion tokens per hour on T4 instances
- 152x edge performance gain from 107K to 16M tokens per second on 4 vCPU instances
- 90% model size reduction while maintaining higher accuracy
- 38x carbon footprint reduction through electrical savings
Ready to Deploy Optimized Models?
See how Perforated BackpropagationTM can transform your deployment costs and performance
Get Started Today