Help models learn more from every training example.
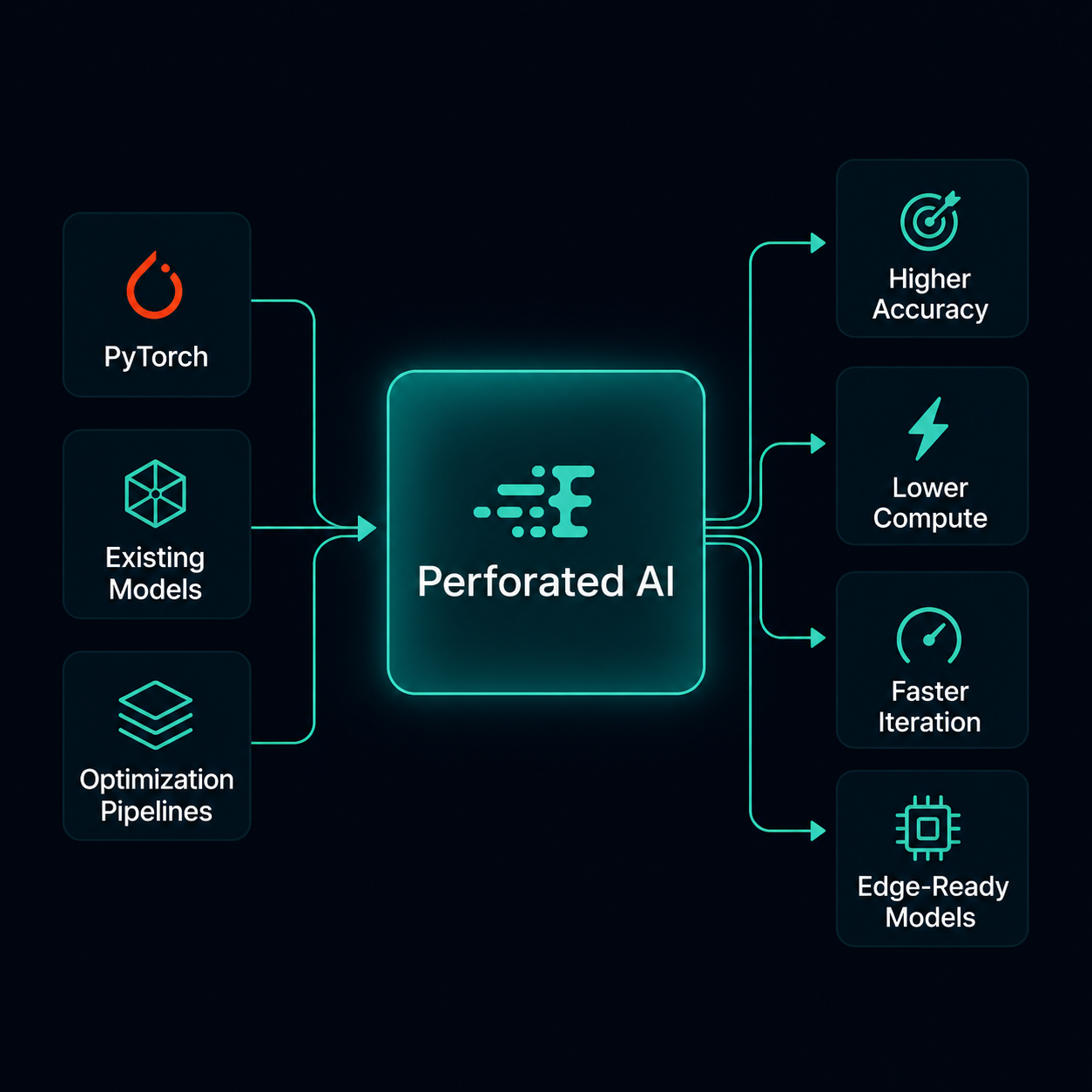
AI teams face three ways to improve model performance.
When model accuracy is not good enough, most teams have three options:
Collect more data
Gather additional labeled examples to improve model learning.
Build larger models
Increase model capacity and parameter count.
Help models learn more efficiently
Extract more value from existing training data.
Most teams focus on the first two. Perforated focuses on the third.
By adding additional learning signals during training, Perforated helps models extract more value from the data they already have.
More accuracy. Fewer examples. Smaller models.
Help models learn more from every training example.
Perforated integrates into existing PyTorch workflows and adds neuron-specific learning signals during training. These signals help models learn more efficiently from available data, improving accuracy without requiring larger datasets or larger models.
- Keep your existing model architecture
- Test against your current validation metrics
- Continue using your existing deployment pipeline
model = perforate_model(model)
while not training_complete:
train_one_epoch()
score = validate()
model, training_complete = pai_tracker.add_validation_score(
score, model
)Representative integration pattern. Exact setup depends on model architecture, dataset, and evaluation metric.
Built for Data-Efficient Training
Designed for ML teams building production AI systems under real-world constraints.
Train With Less Data
Reach target performance with fewer labeled examples.
Improve Existing Models
Extract more value from datasets you already have.
Reduce Annotation Costs
Decrease dependence on expensive labeling cycles.
Build Smaller Models
Achieve strong performance with fewer parameters.
Deploy Efficiently
Carry training gains into production environments.
Integrate Quickly
Works with existing PyTorch workflows.
Get more performance from the data you already have.
Perforated helps teams improve model accuracy through data-efficient training without requiring larger datasets or forcing a model rebuild.
Built for production ML
Integrates Into Existing ML Workflows.
Compatible with existing PyTorch pipelines and designed for fast evaluation inside real-world ML environments. Perforated helps teams improve model performance without changing architectures, redesigning workflows, or adjusting deployment infrastructure.
- Minimal code changes for existing PyTorch workflows
- Test against existing models, datasets, and benchmarks
- Compatible with modern optimization techniques like quantization, pruning, and distillation
Proven In Production.
- Up to 50%
- Less Training Data
- Up to 70%
- Performance Improvement
- Up to 40%
- Faster Iteration Cycles
- Up to 97%
- Lower Deployment Cost
Achieve target accuracy with
fewer labeled examples.
Extract more value from
existing datasets.
Shorten optimization and
deployment timelines.
Smaller models with reduced
resource requirements.
What teams are seeing
"We needed to improve model performance but couldn't afford to label more data. Perforated helped us get better results from what we already had."
ML Engineering Lead
Large Enterprise AI Team
"Integration was surprisingly lightweight. We tested against existing PyTorch models and benchmarks within hours."
Senior Applied AI Engineer
Mid-Stage AI Infrastructure Company
"The efficiency-to-accuracy tradeoff was the biggest surprise. We got better models without collecting more training data."
Computer Vision Team Lead
Autonomous Systems Company
Common Questions
How Perforated integrates into existing ML workflows and helps teams train more efficient models.
What is Perforated?
Perforated is a machine learning company that has created a technology to massively unlock performance for AI/ML models. Based on a recent neuroscience breakthrough, we act as the data-efficiency layer that helps teams build more accurate, parameter-efficient models. For enterprise users, this often means getting the same model performance with half the amount of training data, or recovering half of the remaining error of pruned, parameter-efficient models to achieve much higher levels of accuracy. Ultimately, this translates to saved costs, accelerated timelines, and more value from AI models.
How does Perforated improve machine learning models?
Traditional artificial neurons only sum weighted inputs. Perforated introduces dendritic structures that perform sophisticated computations before signals reach the cell body. This allows models to achieve higher accuracy with fewer parameters, reducing both training data requirements and deployment costs.
Do I need to rebuild my model architecture to use Perforated?
No. Perforated is designed to integrate into your existing PyTorch workflows. You can keep your current model architecture, test against your existing validation metrics, and continue using your standard deployment pipelines without major refactoring. Our engineering team is readily available to support integration efforts and answer any questions.
What are the measurable benefits of using Perforated?
Teams using the Perforated Suite typically see a 30% reduction in training data requirements, 20% error reduction, and 60% parameter reduction. From a business perspective, this means they are drastically lowering deployment and compute costs without sacrificing performance.
Better Models. Less Data.
Evaluate Perforated against your existing models and datasets. Get more performance from the data you already have.